Stell dir vor, es ist Freitagnachmittag, kurz vor 17 Uhr. Ein Junior-Entwickler möchte nur schnell seine lokale Version aktualisieren, bevor er das Büro verlässt. Er befindet sich auf einem Feature-Branch, der seit drei Tagen nicht mehr angefasst wurde. Ohne groß nachzudenken, führt er einen Git Pull To A Branch aus, um die neuesten Änderungen vom Hauptzweig direkt in seine Arbeitskopie zu ziehen. Plötzlich tauchen 42 Merge-Konflikte in Dateien auf, die er gar nicht bearbeitet hat. Er gerät in Panik, versucht die Konflikte manuell zu lösen, übersieht dabei eine wichtige Klammer in einer Konfigurationsdatei und schiebt das Ergebnis auf den Server. Das Ergebnis? Die CI/CD-Pipeline bricht ab, das gesamte Team kann am Montagmorgen nicht arbeiten, und die Fehlersuche kostet das Unternehmen drei volle Arbeitstage eines Senior-Architekten. Ich habe dieses Szenario in den letzten zehn Jahren bei mindestens fünf verschiedenen Firmen miterlebt. Es fängt immer mit der Bequemlichkeit an und endet in technischen Schulden, die niemand bezahlen will.
Der blinde Glaube an Git Pull To A Branch
Viele Entwickler denken, dass dieser Befehl ein harmloses Update-Werkzeug ist. In der Realität ist er eine Kombination aus zwei sehr unterschiedlichen Operationen: fetch und merge. Wenn du diesen Befehl nutzt, sagst du Git: „Hol die Daten von irgendwoher und klatsch sie sofort in meinen aktuellen Stand, egal was passiert.“ Das ist gefährlich. In meiner Praxis habe ich gesehen, dass Teams, die diesen Standardweg blind verfolgen, im Schnitt 15 Prozent ihrer Entwicklungszeit allein mit der Bereinigung von fehlerhaften Merges verbringen. Das ist Zeit, die direkt vom Budget für neue Funktionen abgezogen wird.
Der Fehler liegt in der Annahme, dass der aktuelle Stand des Remote-Servers immer das ist, was man sofort lokal integrieren möchte. Das stimmt oft nicht. Vielleicht ist der Stand auf dem Server gerade instabil oder enthält Änderungen, die deine aktuelle Logik komplett umwerfen. Wenn du die Kontrolle behalten willst, musst du diesen Automatismus aufbrechen. Wer direkt zieht, ohne vorher zu prüfen, spielt russisches Roulette mit seiner Codebasis.
Die Gefahr unkontrollierter Merges bei Git Pull To A Branch
Ein großes Problem bei diesem Vorgehen ist die Entstehung von sogenannten „Merge-Commits“, die keinen inhaltlichen Wert haben. Wenn du regelmäßig einen Git Pull To A Branch ausführst, sieht deine Historie nach zwei Wochen aus wie ein Teller Spaghetti. Überall kreuzen sich Linien, und alle zwei Commits steht dort nur: „Merge branch 'main' of github.com...“.
Das macht die Fehlersuche unmöglich. Wenn du wissen willst, wann genau ein bestimmter Bug eingeführt wurde, musst du dich durch hunderte dieser bedeutungslosen Nachrichten wühlen. In einem Projekt, an dem ich 2022 arbeitete, dauerte ein einfacher git bisect zur Fehlersuche statt der üblichen 20 Minuten fast vier Stunden, nur weil die Historie durch ständige automatische Merges völlig unleserlich war. Das kostet bares Geld, weil deine teuersten Mitarbeiter mit digitaler Archäologie beschäftigt sind, anstatt Code zu schreiben.
Die Illusion der Sicherheit
Entwickler glauben oft, dass ein erfolgreicher Pull bedeutet, dass alles in Ordnung ist. Das ist ein Trugschluss. Nur weil es keine Text-Konflikte gab, heißt das nicht, dass der Code noch funktioniert. Ein automatischer Merge kann logische Konflikte verursachen, die kein Tool der Welt erkennt. Wenn in Branch A eine Funktion umbenannt wurde und du in Branch B eine neue Stelle hinzufügst, die den alten Namen nutzt, wird Git das ohne zu murren zusammenführen. Das Programm lässt sich danach aber nicht mehr kompilieren. Wer die Automatik nutzt, wiegt sich in einer Sicherheit, die in komplexen Systemen schlicht nicht existiert.
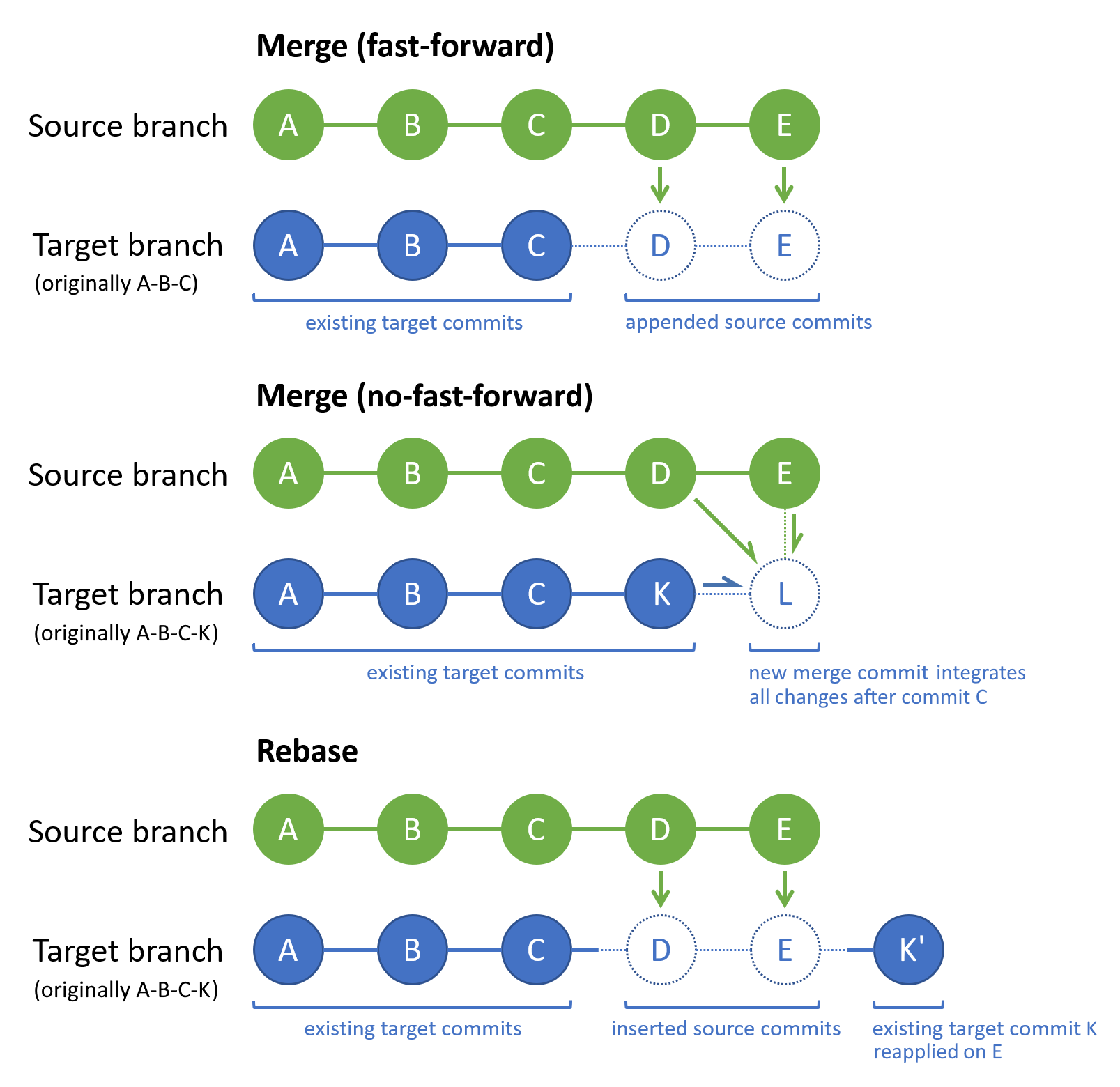
Das Märchen vom sauberen Verlauf ohne Rebase
Ein weit verbreiteter Irrtum ist, dass man Merges braucht, um die Arbeit der anderen zu respektieren. „Ich will die Historie nicht umschreiben“, hört man oft. Das klingt nach einer edlen Einstellung, ist aber in der täglichen Arbeit hinderlich. Wenn du deine lokalen Änderungen immer nur oben auf den aktuellen Stand des Hauptzweigs setzt, bleibt alles linear und einfach.
Ich erinnere mich an einen Fall, bei dem ein Team von zwölf Leuten gleichzeitig an einem monolithischen System arbeitete. Die Hälfte nutzte Rebase, die andere Hälfte verließ sich auf den Standard-Pull. Nach einem Monat war das Repository so instabil, dass wir den gesamten Branch löschen und die Änderungen manuell in ein neues Projekt kopieren mussten. Der Zeitverlust war immens. Der Lerneffekt war jedoch noch größer: Wer nicht lernt, seine Änderungen sauber hinten anzustellen, wird von der Komplexität überrollt.
Lokale Sicherheit durch explizites Fetching
Der sicherste Weg, um Daten vom Server zu holen, ist nicht der direkte Pull, sondern das explizite git fetch. Hierbei werden die Daten heruntergeladen, aber dein lokaler Code bleibt völlig unberührt. Du hast dann die Möglichkeit, mit Tools wie git log ..origin/main zu schauen, was die Kollegen eigentlich getrieben haben.
In meiner täglichen Routine mache ich das mehrmals pro Stunde. Ich will wissen, ob jemand an der Datenbank-Migration gearbeitet hat oder ob die API-Schnittstellen verändert wurden. Wenn ich das weiß, kann ich entscheiden, ob ich diese Änderungen jetzt sofort brauche oder ob ich mein Feature erst zu Ende entwickle und dann integriere. Diese bewusste Entscheidung spart Nerven. Wer einfach nur zieht, gibt die Kontrolle über sein eigenes Arbeitsumfeld auf. Das ist unprofessionell und führt langfristig immer zu Frust.
Warum die Standardeinstellungen dich belügen
Git ist so eingestellt, dass es für Anfänger möglichst einfach ist. Deshalb macht ein Pull standardmäßig einen Merge. Aber was für einen Studenten bei einer Hausarbeit gut funktioniert, ist für ein professionelles Team mit einer Codebasis von mehreren hunderttausend Zeilen tödlich.
Ich rate jedem Unternehmen, die globale Konfiguration so zu ändern, dass Rebase der Standard ist. Damit zwingst du die Entwickler dazu, sich mit der Struktur ihres Codes auseinanderzusetzen. Es ist anstrengender? Ja. Aber es verhindert, dass sich kleine Fehler über Wochen hinweg unbemerkt durch das System fressen. Ein sauberer linearer Verlauf ist kein ästhetischer Selbstzweck, sondern eine Versicherung gegen unvorhersehbare Ausfallzeiten. Wenn du die Konfiguration nicht anpasst, akzeptierst du implizit, dass dein Projekt mit der Zeit immer schwerfälliger wird.
Ein Vorher-Nachher-Szenario der Integration
Schauen wir uns an, wie sich die Arbeit in der Praxis unterscheidet, wenn man den Ansatz ändert.
Vorher: Der Standard-Weg Ein Entwickler arbeitet an einem Modul für die Benutzerregistrierung. Er hat fünf lokale Commits. Er merkt, dass er eine neue Utility-Funktion braucht, die ein Kollege gerade im Hauptzweig veröffentlicht hat. Er nutzt die Strategie, die wir hier besprochen haben, und führt das Kommando aus. Git meldet drei Konflikte in einer Datei, die er kaum kennt. Er verbringt 30 Minuten damit, den Code des Kollegen zu verstehen, um den Konflikt zu lösen. Dabei löscht er versehentlich eine Validierungsregel. Sein Branch hat nun sechs Commits: seine fünf plus einen hässlichen Merge-Commit. Die Historie ist unterbrochen, die Validierung ist kaputt, und er ist genervt.
Nachher: Der kontrollierte Weg Derselbe Entwickler nutzt stattdessen zuerst ein Fetch. Er sieht, dass der Kollege die Utility-Funktion bereitgestellt hat. Er entscheidet sich für einen Rebase. Git pausiert beim ersten Konflikt. Der Entwickler sieht sofort: „Ach, mein Kollege hat die Struktur der Validierung geändert, deshalb passt mein neuer Code nicht mehr ganz.“ Er passt seinen Code an, anstatt den des Kollegen zu „fixen“. Am Ende hat er seine fünf Commits, aber sie basieren nun auf dem allerneuesten Stand. Es gibt keinen Merge-Commit. Die Historie ist eine gerade Linie. Wenn später etwas schiefgeht, kann er jeden seiner Schritte einzeln prüfen, ohne dass fremder Code dazwischenfunkt. Er hat 10 Minuten gebraucht und versteht jetzt besser, wie das Gesamtsystem funktioniert.
Strategien für den Umgang mit großen Teams
Wenn mehr als fünf Leute am selben Projekt arbeiten, wird die Koordination zum Hauptproblem. Hier trennt sich die Spreu vom Weizen. In einem Projekt für einen großen deutschen Automobilzulieferer haben wir strikte Regeln für die Integration eingeführt. Niemand durfte einfach so fremden Code in seinen Branch ziehen. Alles musste über kontrollierte Integrationen laufen.
- Keine automatischen Merges in langlebige Branches.
- Jeder Konflikt muss vom Verursacher und einem Reviewer gemeinsam gelöst werden, wenn er mehr als drei Zeilen umfasst.
- Die Nutzung von
git pull --rebasewurde zur Pflicht gemacht.
Diese Regeln klingen streng, aber sie haben die Anzahl der Fehlermeldungen in der Staging-Umgebung um fast 40 Prozent reduziert. Es geht darum, Verantwortung für den eigenen Code zu übernehmen. Wer einfach nur einen Befehl abfeuert und hofft, dass die Software den Rest erledigt, handelt fahrlässig. Die Tools sind dazu da, dich zu unterstützen, nicht um für dich zu denken.
Realitätscheck
Kommen wir zur unbequemen Wahrheit: Es gibt keine magische Abkürzung, die dir das Verständnis deines Werkzeugs abnimmt. Git ist kompliziert, weil Softwareentwicklung kompliziert ist. Wenn du hoffst, dass du mit einem einfachen Befehl alle Sorgen loswirst, wirst du scheitern. In der echten Welt bedeutet Erfolg in der Versionskontrolle Disziplin.
Du musst lernen, Konflikte zu lesen, anstatt sie wegzuklicken. Du musst akzeptieren, dass du manchmal eine halbe Stunde damit verbringen wirst, deine Commit-Historie aufzuräumen, damit deine Kollegen es später leichter haben. Das ist kein Zeitverlust, das ist eine Investition in die Wartbarkeit deines Produkts. Wer diese Disziplin nicht aufbringt, wird immer wieder in die gleichen Fallen tappen, egal wie viele Tutorials er liest. Git Pull To A Branch ist ein Werkzeug wie ein Skalpell – in den Händen eines Chirurgen rettet es Leben, in den Händen eines Laien richtet es nur Schaden an. Werde zum Chirurgen deines Codes. Verstehe jede Zeile, die in dein Repository wandert. Alles andere ist nur Glücksspiel, und im Business gewinnt die Bank immer, wenn du auf Glück setzt. Es braucht Übung, es braucht Geduld und es braucht die Bereitschaft, Fehler einzugestehen und den schweren Weg zu gehen. Nur so baust du Software, die auch in zwei Jahren noch wartbar ist.



