Das World Wide Web Consortium (W3C) und die Web Hypertext Application Technology Working Group (WHATWG) haben neue Richtlinien für die Handhabung von Datenströmen in Webadressen festgelegt. Diese technischen Anpassungen betreffen primär die Methode Javascript Read Parameter From Url, welche Entwickler weltweit einsetzen, um Informationen aus der Adresszeile eines Browsers zu extrahieren. Laut einer Mitteilung des W3C zielen die Änderungen darauf ab, die Interoperabilität zwischen verschiedenen Browser-Engines wie Chromium, Gecko und WebKit zu verbessern.
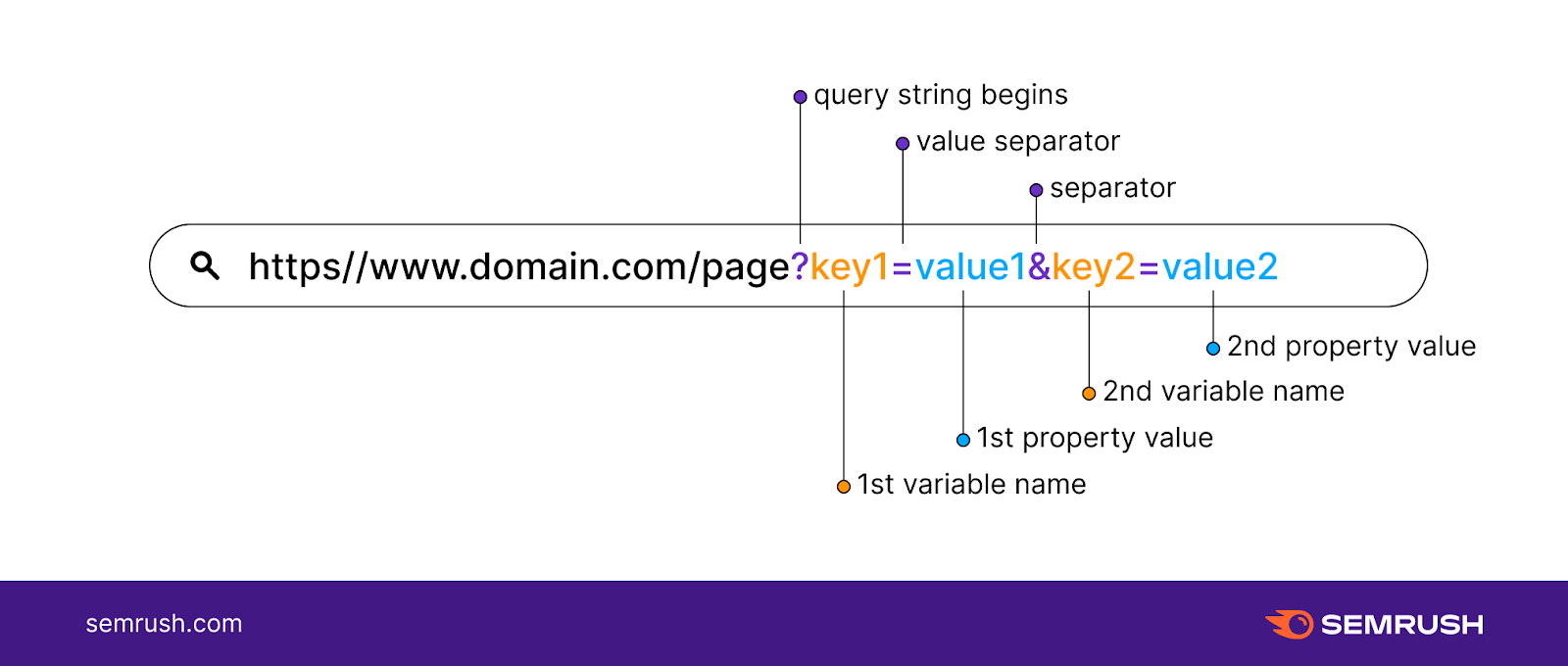
Technisch gesehen stützen sich moderne Anwendungen auf die URL-Schnittstelle, die im WHATWG URL Living Standard definiert ist. Diese Spezifikation regelt, wie Browser Zeichenketten interpretieren, die nach einem Fragezeichen in der Webadresse erscheinen. Die Relevanz dieser Standardisierung wächst, da immer mehr zustandslose Webanwendungen auf diese Art der Informationsweitergabe angewiesen sind.
Die Evolution Der Javascript Read Parameter From Url Schnittstelle
In der frühen Phase der Webentwicklung griffen Programmierer oft auf komplexe reguläre Ausdrücke zurück, um Daten aus der Location-Eigenschaft des Fensterobjekts zu gewinnen. Die Einführung des URLSearchParams-Objekts durch die Browser-Hersteller markierte einen Wandel in der Effizienz dieser Prozesse. Laut Dokumentationen des Mozilla Developer Network ermöglicht diese Schnittstelle den direkten Zugriff auf einzelne Schlüssel-Wert-Paare einer Abfragezeichenkette.
Diese moderne Herkunft der Datenverarbeitung ersetzt zunehmend manuelle Parsing-Methoden, die anfällig für Fehler bei der Zeichenkodierung waren. Die URLSearchParams-API bietet Methoden wie „get" oder „has", um die Präsenz bestimmter Informationen zu prüfen. Experten der Internet Engineering Task Force (IETF) betonen in RFC 3986 die Notwendigkeit, Trennzeichen wie das kaufmännische Und-Zeichen sowie Gleichheitszeichen strikt zu interpretieren.
Die Implementierung erfolgt heute meist über einen Konstruktor, der die aktuelle Adresse als Argument akzeptiert. Durch diese Standardisierung reduziert sich der Codeaufwand für Entwickler erheblich. Software-Architekten von Unternehmen wie Microsoft und Google unterstützen diese Vereinheitlichung, um die Ladezeiten von Skripten zu minimieren.
Technische Unterschiede Bei Der Implementierung Von Suchparametern
Obwohl die URLSearchParams-API weit verbreitet ist, existieren feine Unterschiede in der Art und Weise, wie Sonderzeichen behandelt werden. Ein illustratives Beispiel wäre die Handhabung von Pluszeichen, die in manchen Kontexten als Leerzeichen interpretiert werden, während andere Systeme eine prozentuale Kodierung verlangen. Das W3C arbeitet daran, diese Diskrepanzen durch präzisere Test-Suites zu eliminieren.
Entwickler müssen sicherstellen, dass die verwendete Logik auch mit älteren Browser-Versionen kompatibel bleibt, sofern diese kein URLSearchParams unterstützen. In solchen Fällen kommen oft sogenannte Polyfills zum Einsatz. Diese kleinen Skripte simulieren die moderne Funktionalität in Umgebungen, die den aktuellen Standard noch nicht nativ beherrschen.
Sicherheitsbedenken Bei Der Verwendung Von Javascript Read Parameter From Url
Sicherheitsexperten des Open Web Application Security Project (OWASP) warnen regelmäßig vor den Risiken, die mit der Extraktion von Daten aus Webadressen verbunden sind. Angreifer nutzen oft manipulierte Parameter, um Cross-Site Scripting (XSS) Angriffe durchzuführen. Wenn eine Anwendung Daten direkt aus der URL liest und ungefiltert im Dokumentenobjektmodell (DOM) anzeigt, entsteht eine kritische Schwachstelle.
Laut dem OWASP Top 10 Report bleibt die Injektion von bösartigem Code eine der größten Bedrohungen für webbasierte Systeme. Die Organisation empfiehlt dringend, alle aus der Adresszeile gewonnenen Informationen zu validieren und zu maskieren. Nur durch eine strikte Trennung von Daten und ausführbarem Code lässt sich die Integrität der Nutzersitzung gewährleisten.
Zusätzlich zur Injektionsgefahr besteht das Risiko des Informationsabflusses. Sensible Daten wie Session-IDs oder persönliche Identifikationsmerkmale sollten niemals in der URL übertragen werden. Server-Logs und Browser-Verläufe speichern diese Adressen oft im Klartext, was den Datenschutz gefährdet. Die Datenschutz-Grundverordnung (DSGVO) der Europäischen Union stellt hier hohe Anforderungen an die technische Umsetzung der Datensparsamkeit.
Kritik An Der Clientseitigen Datenverarbeitung
Einige Kritiker innerhalb der Entwicklergemeinde bemängeln die wachsende Abhängigkeit von clientseitiger Logik für sicherheitsrelevante Funktionen. Sie argumentieren, dass die Validierung von Parametern ausschließlich auf dem Server stattfinden sollte. Ein Angreifer kann den clientseitigen Code leicht umgehen oder manipulieren, was die lokale Prüfung wirkungslos macht.
Große Plattformen wie GitHub oder Amazon setzen daher auf hybride Modelle. Während die Benutzeroberfläche schnell auf URL-Änderungen reagiert, findet die tatsächliche Datenverarbeitung im Hintergrund auf geschützten Servern statt. Diese Architektur minimiert die Angriffsfläche und erhöht die Stabilität der Anwendung bei unvorhergesehenen Eingaben.
Performance Und Effizienz Moderner Webanwendungen
Die Geschwindigkeit, mit der eine Webseite auf Benutzereingaben reagiert, ist ein wesentlicher Faktor für die Nutzererfahrung. Studien von Google zeigen, dass bereits Verzögerungen im Millisekundenbereich die Absprungrate signifikant erhöhen. Die Verwendung nativer Browser-Funktionen zum Auslesen von Parametern trägt zur Optimierung dieser Leistung bei.
Da moderne Browser die URL-Verarbeitung in hochoptimiertem C++ Code ausführen, sind diese Operationen wesentlich schneller als interpretierte JavaScript-Schleifen. Die Reduzierung der Rechenlast auf dem Haupt-Thread sorgt für eine flüssigere Darstellung von Animationen und Interaktionen. Dies ist besonders auf mobilen Endgeräten mit begrenzter Prozessorleistung von Bedeutung.
Frameworks wie React, Vue oder Angular haben eigene Abstraktionsebenen geschaffen, um den Zugriff auf Routen-Parameter zu vereinfachen. Diese Bibliotheken nutzen intern die Standard-APIs des Browsers, bieten aber eine deklarative Syntax an. Dies erleichtert die Wartung von großem Code-Basen in professionellen Entwicklungsumgebungen.
Integration In Single Page Applications
In sogenannten Single Page Applications (SPA) ändert sich die URL oft, ohne dass die Seite neu geladen wird. Dies geschieht über die History-API des Browsers. Die Verknüpfung dieser API mit der Parameter-Extraktion ermöglicht es, den Zustand der Anwendung direkt in der Adresszeile abzubilden. Nutzer können so spezifische Zustände einer Applikation über Lesezeichen speichern oder teilen.
Die Herausforderung besteht darin, die Synchronisation zwischen dem internen Anwendungszustand und der externen URL konsistent zu halten. Fehler in dieser Logik führen oft dazu, dass die Zurück-Taste des Browsers nicht wie vom Nutzer erwartet funktioniert. Software-Tester verwenden automatisierte Tools, um solche Navigationsfehler frühzeitig im Entwicklungszyklus zu identifizieren.
Regulatorische Rahmenbedingungen Und Industriestandards
Die technische Umsetzung der Parameter-Verarbeitung unterliegt zunehmend rechtlichen Rahmenbedingungen. Die European Union Agency for Cybersecurity (ENISA) veröffentlicht regelmäßig Leitfäden für die sichere Softwareentwicklung. Diese Dokumente betonen die Bedeutung von Standard-konformen Implementierungen, um systemische Risiken im digitalen Binnenmarkt zu reduzieren.
Industrie-Konsortien wie die Digital Advertising Alliance (DAA) beobachten die Entwicklungen ebenfalls genau. Viele Tracking-Mechanismen für Online-Werbung basieren auf Parametern in der URL. Da Browser-Hersteller wie Apple mit Safari und Mozilla mit Firefox den Schutz der Privatsphäre verstärken, ändern sich die technischen Möglichkeiten für diese Form der Datenerhebung kontinuierlich.
Die Einführung von „Query Parameter Stripping" in einigen Browsern entfernt automatisch bekannte Tracking-Parameter aus der Adresse. Dies führt zu Konflikten zwischen Werbetreibenden und Software-Herstellern. Während die einen den Schutz der Nutzerdaten priorisieren, sehen die anderen eine Beeinträchtigung ihrer Geschäftsmodelle.
Technologische Implikationen Für Die Softwarearchitektur
Die Entscheidung, wie Informationen innerhalb einer Webanwendung fließen, beeinflusst die gesamte Systemarchitektur. Architekten müssen abwägen, welche Daten in der URL sichtbar sein dürfen und welche im internen Speicher verbleiben müssen. Eine klare Trennung zwischen Navigationszustand und Anwendungsdaten ist hierbei das Ziel.
In großen Unternehmen werden hierfür oft interne Standards definiert, die über die offiziellen W3C-Richtlinien hinausgehen. Diese Richtlinien legen fest, welche Schlüsselwörter für Parameter reserviert sind und wie diese benannt werden müssen. Eine einheitliche Namensgebung verbessert die Lesbarkeit der Adressen und erleichtert die Fehlersuche über verschiedene Teams hinweg.
Automatisierte CI/CD-Pipelines prüfen den Code heute oft schon während der Erstellung auf die korrekte Verwendung der APIs. Statische Code-Analyse-Tools wie ESLint verfügen über Regeln, die vor unsicheren Mustern beim Auslesen von URL-Daten warnen. Diese technologische Unterstützung reduziert die Wahrscheinlichkeit, dass bekannte Sicherheitslücken in die Produktion gelangen.
Zukunft Der Webnavigation Und Datentransferprotokolle
Die Entwicklung bleibt nicht bei der aktuellen URL-Schnittstelle stehen. Das W3C diskutiert bereits über neue Konzepte wie „Navigation API", die den Umgang mit Adressänderungen grundlegend modernisieren soll. Ziel ist es, die Komplexität der aktuellen History-Schnittstelle zu verringern und eine robustere Basis für Webanwendungen zu schaffen.
Ein weiterer Trend ist die zunehmende Verschlüsselung von Parametern direkt im Browser. Durch die Verwendung von Web-Cryptography-APIs könnten sensible Informationen in der URL so kodiert werden, dass nur der autorisierte Empfänger sie lesen kann. Dies würde die Vorteile der URL-basierten Zustandsübermittlung mit hohen Sicherheitsstandards kombinieren.
In den kommenden Jahren wird beobachtet werden, wie sich das Gleichgewicht zwischen technischer Funktionalität, Sicherheit und Datenschutz weiter verschiebt. Die Browser-Hersteller spielen hierbei eine zentrale Rolle, da sie durch ihre Implementierungen faktische Standards setzen. Die Fachwelt erwartet für das nächste Jahr weitere Spezifikationsentwürfe, die insbesondere die Privatsphäre der Endnutzer stärker in den Fokus rücken werden.
Ob die klassische Methode Javascript Read Parameter From Url langfristig durch neue Protokolle ersetzt wird, bleibt eine offene Frage unter Experten. Sicher ist jedoch, dass die Standardisierung der Web-Technologien weiter voranschreiten wird, um ein stabiles und sicheres Internet für alle Teilnehmer zu gewährleisten. Die nächsten Sitzungen der WHATWG-Arbeitsgruppen im Herbst werden voraussichtlich erste Details zu den geplanten Erweiterungen des URL-Standards liefern.



