Die automatisierte Verarbeitung von Massendaten gewinnt in deutschen Industrieunternehmen zunehmend an Relevanz für die Optimierung betrieblicher Abläufe. Softwareingenieure setzen verstärkt auf standardisierte Skripte wie ein Python Program To Read A Text File, um unstrukturierte Protokolle in maschinenlesbare Formate zu überführen. Laut einer Analyse des Digitalverbands Bitkom nutzen bereits 74 Prozent der Unternehmen in Deutschland Werkzeuge der Datenanalyse zur Steuerung ihrer Geschäftsprozesse. Die Effizienz dieser Anwendungen hängt maßgeblich von der Geschwindigkeit der Dateneingabe ab, wobei einfache Dateizugriffe das Fundament bilden.
Die Programmiersprache Python hat sich dabei als Marktführer etabliert, da ihre Syntax eine schnelle Implementierung technischer Lösungen ermöglicht. Experten des Fraunhofer-Instituts für Intelligente Analyse- und Informationssysteme (IAIS) stellten fest, dass die Reduktion von Codezeilen die Fehlerquote in der Softwareentwicklung signifikant senkt. Die Fähigkeit, externe Quellen sicher anzubinden, stellt eine Grundvoraussetzung für die moderne IT-Infrastruktur dar. In der industriellen Praxis werden solche Mechanismen verwendet, um Sensordaten von Fertigungsstraßen in Echtzeit auszuwerten und Wartungsintervalle präziser zu planen.
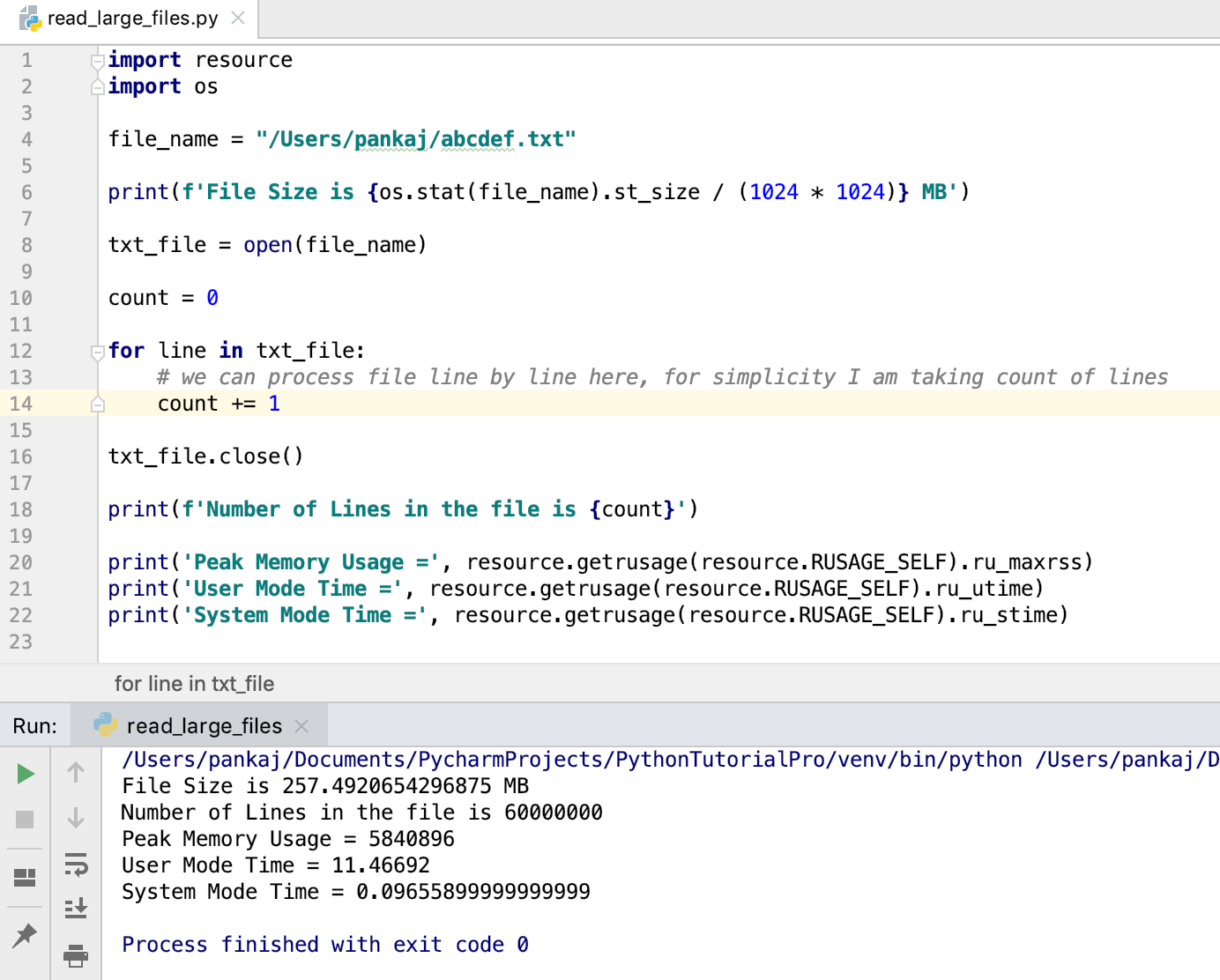
Technische Implementierung Einem Python Program To Read A Text File Im Unternehmenseinsatz
Der Zugriff auf Dateisysteme erfolgt unter Python primär über die integrierte open-Funktion, die eine Brücke zwischen dem Betriebssystem und der Anwendung schlägt. Entwickler nutzen hierbei oft den Kontextmanager with, um sicherzustellen, dass Systemressourcen nach dem Lesevorgang unmittelbar wieder freigegeben werden. Diese Methode verhindert Speicherlecks, die in Langzeitanwendungen zu Systemabstürzen führen können. Dokumentationen der Python Software Foundation betonen die Wichtigkeit der korrekten Kodierung, insbesondere bei der Verarbeitung von Sonderzeichen im deutschsprachigen Raum.
Sicherheitsaspekte Beim Dateizugriff
Sicherheitsrelevante Aspekte spielen eine zentrale Rolle, wenn externe Eingaben verarbeitet werden sollen. Christian Grothoff, Professor für Netzwerksicherheit, wies in verschiedenen Publikationen darauf hin, dass unvalidierte Dateipfade ein Einfallstor für Verzeichnis-Traversal-Angriffe darstellen können. Unternehmen implementieren daher zusätzliche Prüfroutinen, bevor ein Python Program To Read A Text File ausgeführt wird. Diese Routinen gleichen den angeforderten Pfad mit einer Liste erlaubter Verzeichnisse ab und unterbinden den Zugriff auf sensible Systemdateien.
Die Handhabung großer Datenmengen erfordert zudem Strategien zum zeilenweisen Einlesen, um den Arbeitsspeicher zu entlasten. Anstatt den gesamten Inhalt einer Datei auf einmal zu laden, iterieren Programme über die einzelnen Zeilen. Dieses Vorgehen ermöglicht die Analyse von Gigabyte-großen Logdateien auf Standard-Hardware. In Rechenzentren führt diese Praxis zu einer besseren Skalierbarkeit der Dienste bei gleichzeitig sinkenden Energiekosten für die Kühlung der Server.
Ökonomische Auswirkungen Automatisierter Datenverarbeitung
Der wirtschaftliche Nutzen der automatisierten Textextraktion lässt sich in eingesparten Arbeitsstunden beziffern. Eine Studie der Unternehmensberatung McKinsey schätzt, dass durch die Automatisierung repetitiver Aufgaben die Produktivität in technischen Abteilungen um bis zu 25 Prozent steigen kann. Die schnelle Integration von Textdaten aus verschiedenen Quellen erlaubt es Firmen, schneller auf Marktveränderungen zu reagieren. Manuelle Dateneingaben werden durch Skripte ersetzt, was die personellen Ressourcen für komplexere Problemlösungen freisetzt.
Kostenstrukturen Und Lizenzmodelle
Ein Vorteil bei der Verwendung von Python liegt in der Open-Source-Natur der Sprache, die keine Lizenzgebühren verursacht. Firmen sparen im Vergleich zu proprietären Lösungen erhebliche Kosten bei der Skalierung ihrer Software-Projekte. Die breite Verfügbarkeit von Bibliotheken reduziert die Entwicklungszeit für neue Funktionen von Wochen auf wenige Tage. Dies fördert die Innovationskraft kleiner und mittlerer Unternehmen, die über begrenzte Budgets für Forschung und Entwicklung verfügen.
Trotz der Kostenvorteile entstehen Ausgaben für die Schulung von Personal und die Wartung der Codebasis. Veralteter Code kann Sicherheitslücken aufreißen, wenn er nicht regelmäßig an neue Versionen der Laufzeitumgebung angepasst wird. IT-Abteilungen müssen daher Budget für technisches Refactoring einplanen, um die Langlebigkeit ihrer Lösungen zu garantieren. Die Abhängigkeit von externen Modulen erfordert zudem ein aktives Management der Software-Lieferkette.
Herausforderungen Bei Der Standardisierung Von Dateiformaten
Die Vielfalt an Dateikodierungen wie UTF-8 oder ISO-8859-1 führt in der Praxis häufig zu Komplikationen bei der Datenmigration. Wenn ein Skript eine Datei mit der falschen Kodierung öffnet, resultiert dies in beschädigten Datensätzen oder Programmabbrüchen. Das Deutsche Institut für Normung (DIN) arbeitet an Richtlinien für den Datenaustausch, um solche Inkompatibilitäten zu minimieren. Dennoch müssen Entwickler oft individuelle Anpassungen vornehmen, um historische Datenbestände nutzbar zu machen.
Ein weiteres Problem stellt die Strukturierung innerhalb der Textdateien dar, die oft keinem festen Schema folgt. Während CSV-Dateien noch relativ einfach zu parsen sind, erfordern Freitextprotokolle komplexe reguläre Ausdrücke oder Verfahren der natürlichen Sprachverarbeitung. Viele Organisationen unterschätzen den Aufwand, der für die Bereinigung dieser Rohdaten erforderlich ist. Ohne eine saubere Datenbasis liefern auch die fortschrittlichsten Analysemodelle keine verlässlichen Ergebnisse für die Geschäftsführung.
Integration In Cloudbasierte Infrastrukturen
Die Verlagerung von IT-Ressourcen in die Cloud verändert die Art und Weise, wie Dateizugriffe organisiert werden. Anstatt auf lokale Festplatten zuzugreifen, kommunizieren Programme nun mit Objektspeichern über Programmierschnittstellen (APIs). Provider wie Amazon Web Services oder Microsoft Azure bieten spezifische Software Development Kits an, die diese Kommunikation abstrahieren. Die Kernlogik der Datenverarbeitung bleibt dabei weitgehend identisch, während sich die Zugriffsprotokolle wandeln.
Cloud-native Anwendungen profitieren von der elastischen Skalierung, bei der Rechenleistung je nach Bedarf automatisch hinzugebucht wird. Dies ist besonders bei saisonalen Lastspitzen relevant, etwa im E-Commerce nach großen Werbeaktionen. Die Kostenmodelle der Cloud-Anbieter basieren oft auf der Anzahl der Zugriffe und dem übertragenen Datenvolumen. Eine effiziente Programmierung der Lesevorgänge trägt somit direkt zur Reduktion der monatlichen Betriebskosten bei.
Kritische Betrachtung Der Automatisierungstrends
Kritiker mahnen an, dass die zunehmende Automatisierung der Datenverarbeitung auch Risiken für die Datensouveränität birgt. Wenn Unternehmen sensible Informationen unverschlüsselt in Textdateien speichern, erhöhen sie die Gefahr von Datenabflüssen bei Hackerangriffen. Die Datenschutz-Grundverordnung (DSGVO) stellt hohe Anforderungen an den Umgang mit personenbezogenen Daten, die auch für automatisierte Skripte gelten. Verstöße können Bußgelder in Millionenhöhe nach sich ziehen, was eine lückenlose Dokumentation der Datenflüsse erforderlich macht.
Zudem besteht die Gefahr einer technologischen Monokultur, wenn sich die Industrie zu stark auf eine einzelne Programmiersprache verlässt. Sollten in der Python-Laufzeitumgebung kritische Schwachstellen entdeckt werden, wären weltweit Millionen von Systemen gleichzeitig bedroht. Diversität in der Technologiewahl wird daher von einigen Sicherheitsforschern als notwendige Strategie zur Risikominimierung angesehen. Dennoch überwiegen derzeit die Vorteile der hohen Interoperabilität und der großen Entwicklergemeinschaft.
In den kommenden Monaten wird die Integration von künstlicher Intelligenz in einfache Verarbeitungsroutinen weiter zunehmen. Es bleibt abzuwarten, wie sich die Standards für den sicheren Datenaustausch zwischen unterschiedlichen Plattformen entwickeln werden. Die Branche beobachtet gespannt die Gesetzgebungsverfahren auf EU-Ebene, die den Einsatz von automatisierten Systemen stärker regulieren könnten. Offene Fragen zur Haftung bei fehlerhaften automatisierten Entscheidungen müssen durch die Rechtsprechung in naher Zukunft geklärt werden.



