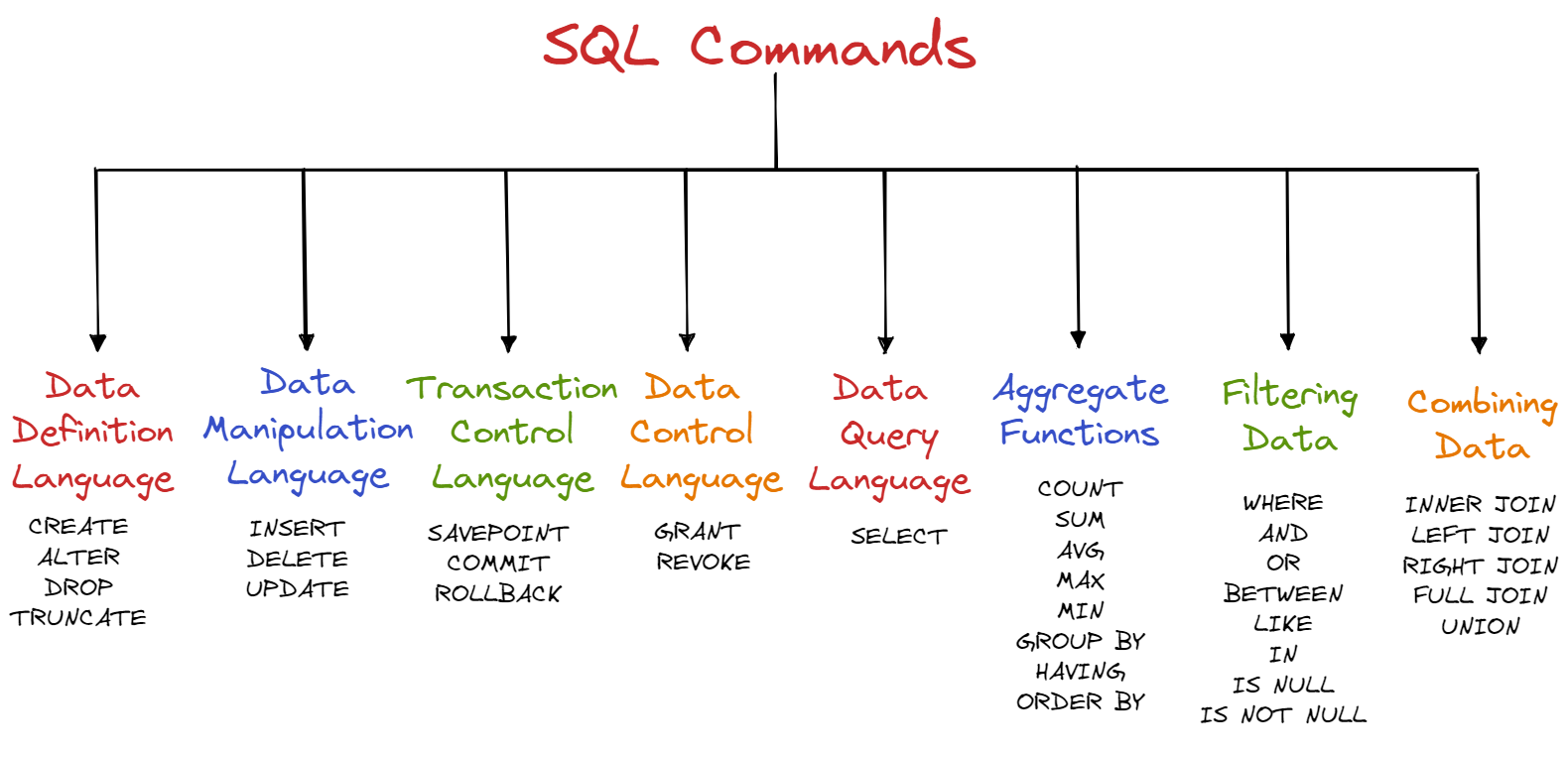
Das American National Standards Institute und die International Organization for Standardization haben in ihrem jüngsten Bericht die technischen Anforderungen für And And Or In Sql präzisiert. Diese Spezifikationen betreffen die logische Verknüpfung von Datensätzen in relationalen Datenbankmanagementsystemen, die weltweit das Rückgrat der digitalen Infrastruktur bilden. Die Neuerung zielt darauf ab, Missverständnisse bei komplexen Abfragen zu reduzieren, die in der Vergangenheit zu erheblichen Performanceverlusten in Rechenzentren führten. Experten der Arbeitsgruppe ISO/IEC JTC 1/SC 32 erklärten in Genf, dass eine fehlerhafte Anwendung logischer Operatoren die Sicherheit von Transaktionen gefährden könne.
Die Relevanz dieser technischen Feinheiten zeigt sich besonders bei der Verarbeitung großer Datenmengen in der Cloud-Architektur. Laut einer Analyse der Cloud Native Computing Foundation hängen effiziente Datenabfragen von der korrekten Priorisierung logischer Ausdrücke ab. Die Entwicklergemeinschaft beobachtet seit Jahren, dass die Vermischung von Filtern ohne explizite Klammersetzung zu unvorhersehbaren Ergebnissen führt. Donald Chamberlin, einer der Mitbegründer der ursprünglichen Datenbanksprache, wies in technischen Publikationen wiederholt darauf hin, dass die logische Hierarchie die Integrität der Ergebnismengen bestimmt.
Historische Entwicklung und die Logik von And And Or In Sql
Die Entstehung der Sprache geht auf die frühen 1970er Jahre zurück, als Edgar F. Codd das relationale Modell bei IBM entwickelte. In den ersten Dokumentationen spielten die logischen Operatoren eine zentrale Rolle, um Datenmengen mathematisch präzise einzugrenzen. Die International Organization for Standardization pflegt seit 1987 den offiziellen Standard, der regelmäßig an moderne Anforderungen angepasst wird. Diese kontinuierliche Pflege stellt sicher, dass Systeme verschiedener Hersteller wie Oracle, Microsoft und IBM kompatibel bleiben.
Innerhalb dieser Entwicklung erwies sich die Kombination verschiedener Filterbedingungen oft als Fehlerquelle. Programmierer unterschätzten häufig die Bindungskraft des Und-Operators gegenüber dem Oder-Operator. Ohne klare Definitionen innerhalb der Syntaxanweisungen interpretierten verschiedene Datenbank-Engines dieselbe Anfrage auf unterschiedliche Weise. Dies führte dazu, dass Unternehmen bei der Migration ihrer Bestände zwischen verschiedenen Anbietern mit Inkonsistenzen in ihren Berichten konfrontiert wurden.
Die Mathematische Grundlage der Logikgatter
Jede Abfrage basiert auf der Boole'schen Algebra, die bereits im 19. Jahrhundert von George Boole definiert wurde. In der Informatik bedeutet dies, dass jede Bedingung entweder als wahr oder falsch gewertet wird. Die Kombination dieser Zustände bildet das Fundament für die Selektion von Informationen aus Tabellen mit Millionen von Einträgen. Ohne diese mathematische Strenge wäre eine zuverlässige Datenverarbeitung in Finanzsystemen oder der Logistik nicht möglich.
Die Implementierung dieser Logik in den 1970er Jahren folgte strengen Regeln der formalen Logik. Während die Hardwarekapazitäten wuchsen, blieb die zugrunde liegende Syntax weitgehend stabil. Dennoch erforderten spezialisierte Anwendungsfälle wie die Bioinformatik oder die Echtzeit-Analyse von Sensordaten eine präzisere Handhabung der Verknüpfungen. Die Standardisierungsgremien mussten daher Richtlinien entwerfen, die sowohl die Abwärtskompatibilität als auch die Leistung moderner Systeme berücksichtigen.
Technische Implementierung und Performance-Herausforderungen
Moderne Datenbank-Optimierer verwenden komplexe Algorithmen, um den effizientesten Weg für die Ausführung einer Abfrage zu finden. Der sogenannte Query Optimizer analysiert die logischen Strukturen und entscheidet, welche Indizes genutzt werden sollen. Laut Dokumentationen von PostgreSQL kann eine ungünstige Anordnung von Filterkriterien dazu führen, dass das System einen vollständigen Tabellenscan durchführen muss. Dies verlangsamt die Antwortzeiten bei Webanwendungen spürbar und erhöht die Betriebskosten für die Serverinfrastruktur.
Ingenieure bei großen Cloud-Anbietern wie Amazon Web Services betonen, dass die Reihenfolge der Operatoren direkten Einfluss auf den Speicherverbrauch hat. Wenn logische Ausdrücke unklar formuliert sind, muss der Optimierer konservative Annahmen treffen. Dies verhindert oft die Nutzung von Parallelisierungsstrategien, die eigentlich für moderne Mehrkernprozessoren vorgesehen sind. Die Fehlersuche in solchen Fällen gestaltet sich schwierig, da die Abfrage zwar technisch korrekt ist, aber das falsche Ergebnis liefert.
Optimierung durch Indizierung und Statistiken
Um die Effizienz zu steigern, sammeln Datenbanken Statistiken über die Verteilung der Werte in den Spalten. Diese Daten helfen dem System zu entscheiden, ob eine Bedingung zuerst geprüft werden sollte, um die Menge der zu untersuchenden Zeilen schnell zu reduzieren. Wenn ein Filter sehr selektiv ist, spart die frühe Anwendung Rechenzeit. Die logische Verknüpfung mehrerer solcher Filter erfordert jedoch eine präzise Kenntnis der Datenstruktur durch den Entwickler.
In der Praxis zeigt sich, dass automatisierte Werkzeuge zur Code-Erstellung oft suboptimalen Code generieren. Diese Tools priorisieren die Lesbarkeit des Codes gegenüber der Ausführungsgeschwindigkeit. Erfahrene Datenbankadministratoren greifen daher oft manuell ein, um die logischen Pfade zu korrigieren. Sie nutzen Analysebefehle, um den Ausführungsplan sichtbar zu machen und Engpässe zu identifizieren, die durch komplexe logische Ketten entstehen.
Kritik an der Komplexität moderner Datenbankabfragen
Trotz der Standardisierung gibt es innerhalb der Entwicklergemeinschaft Kritik an der zunehmenden Komplexität der Syntaxregeln. Kritiker wie der Softwarearchitekt Martin Fowler merkten an, dass die Abstraktionsebene zwischen dem logischen Wunsch des Nutzers und der tatsächlichen Ausführung zu groß geworden sei. Dies führe dazu, dass selbst erfahrene Entwickler Fehler bei der Verwendung von And And Or In Sql machen. Die Folge sind Sicherheitslücken, da falsch gefilterte Daten unbefugten Zugriff ermöglichen könnten.
Ein weiterer Kritikpunkt betrifft die proprietären Erweiterungen vieler Hersteller. Obwohl ein Grundstandard existiert, führen Unternehmen wie Oracle oder Microsoft oft eigene Funktionen ein, die vom Standard abweichen. Dies erschwert die Portabilität von Anwendungen und bindet Kunden langfristig an einen Anbieter. Open-Source-Aktivisten fordern daher eine strengere Einhaltung der ISO-Vorgaben, um den Wettbewerb zu fördern und die technische Transparenz zu erhöhen.
Sicherheitsrisiken durch fehlerhafte Logik
Besonders im Bereich der Cybersicherheit stellen falsch formulierte Abfragen ein erhebliches Risiko dar. Angreifer nutzen Techniken wie die Injektion von Schadcode aus, um die logische Struktur einer Abfrage zu verändern. Durch das Einfügen zusätzlicher Operatoren können sie die Zugriffskontrollen umgehen und vertrauliche Informationen auslesen. Das Bundesamt für Sicherheit in der Informationstechnik warnt in seinen Berichten regelmäßig vor solchen Schwachstellen in Webanwendungen.
Die Prävention solcher Angriffe erfordert eine strikte Trennung von Daten und Logik. Entwickler müssen darauf achten, dass Benutzereingaben niemals direkt in die Struktur der Abfrage einfließen. Stattdessen sollten vorbereitete Anweisungen verwendet werden, die die logische Struktur fest vorgeben. Dennoch bleibt die korrekte Gestaltung der internen Logik die Aufgabe des Programmierers, was eine ständige Weiterbildung und Prüfung der verwendeten Filterkriterien notwendig macht.
Branchenspezifische Anwendungen und Datenintegrität
In der Finanzindustrie ist die Integrität der Datenverarbeitung von existenzieller Bedeutung. Banken müssen sicherstellen, dass Transaktionen unter allen Umständen korrekt verbucht werden. Hier kommen hochspezialisierte Datenbanksysteme zum Einsatz, die eine strikte Einhaltung der ACID-Eigenschaften garantieren. Diese Eigenschaften stellen sicher, dass Transaktionen atomar, konsistent, isoliert und dauerhaft sind. Jede Abfrage, die in diesen Systemen läuft, unterliegt strengsten Qualitätskontrollen.
Auch im Gesundheitswesen spielt die korrekte Filterung von Patientendaten eine entscheidende Rolle. Bei der Analyse von Laborwerten müssen Ärzte sich darauf verlassen können, dass die digitalen Systeme die richtigen Datensätze korrelieren. Eine Verwechslung oder ein Auslassen von Informationen aufgrund logischer Fehler könnte lebensbedrohliche Konsequenzen haben. Hier setzen Institutionen auf zertifizierte Softwarelösungen, die nach internationalen Standards wie HL7 entwickelt wurden.
Die Rolle der Künstlichen Intelligenz bei der Abfrageoptimierung
Ein neuer Trend ist der Einsatz von maschinellem Lernen, um die Leistung von Datenbanken zu verbessern. Diese Systeme lernen aus vergangenen Abfragen und passen die internen Strukturen automatisch an. Forscher am Massachusetts Institute of Technology haben gezeigt, dass KI-gestützte Optimierer klassische Algorithmen in bestimmten Szenarien übertreffen können. Sie erkennen Muster in den Datenzugriffen, die für menschliche Administratoren zu komplex sind.
Allerdings warnen Experten vor einer zu starken Abhängigkeit von Black-Box-Systemen. Wenn eine KI entscheidet, wie eine logische Verknüpfung ausgeführt wird, entzieht sich dies der menschlichen Kontrolle. In regulierten Branchen wie der Luftfahrt oder dem Bankwesen ist die Nachvollziehbarkeit jeder Entscheidung jedoch gesetzlich vorgeschrieben. Daher wird derzeit an erklärbarer KI gearbeitet, die ihre Optimierungsschritte für den Menschen verständlich dokumentiert.
Wirtschaftliche Auswirkungen ineffizienter Datenverarbeitung
Die Kosten für ineffiziente IT-Systeme belaufen sich weltweit auf Milliardenbeträge. Unternehmen investieren hohe Summen in Hardware-Upgrades, um langsame Software zu kompensieren. Eine Studie der Association for Computing Machinery weist darauf hin, dass eine Optimierung der zugrunde liegenden Abfragelogik oft effektiver ist als der Kauf neuer Server. Viele Organisationen unterschätzen das Einsparpotenzial, das in der Bereinigung ihres Datenbank-Codes liegt.
Zudem führen langsame Systeme zu Produktivitätsverlusten bei den Mitarbeitern. Wenn interne Datenbanken für einfache Berichte Minuten statt Sekunden benötigen, summiert sich dieser Zeitverlust über das gesamte Jahr. Im E-Commerce kann eine Verzögerung von nur wenigen Millisekunden bei der Suche zu einem messbaren Rückgang der Verkaufszahlen führen. Kunden erwarten heute eine sofortige Reaktion der digitalen Schnittstellen, was die Anforderungen an die Abfrageeffizienz weiter erhöht.
Ausbildung und Fachkräftemangel
Ein Hindernis bei der Umsetzung effizienter Systeme ist der Mangel an qualifizierten Datenbankspezialisten. Viele Informatik-Studiengänge konzentrieren sich heute auf neue Frameworks und vernachlässigen die Grundlagen der relationalen Logik. Dies führt dazu, dass junge Entwickler zwar komplexe Benutzeroberflächen bauen können, aber Schwierigkeiten haben, die Datenhaltung im Hintergrund performant zu gestalten. Fachverbände fordern daher eine Rückbesinnung auf die Kernkompetenzen der Informatik in der akademischen Ausbildung.
Unternehmen versuchen diesen Mangel durch interne Schulungsprogramme auszugleichen. Große Tech-Konzerne bieten eigene Zertifizierungen an, um sicherzustellen, dass ihre Mitarbeiter die spezifischen Anforderungen ihrer Systeme verstehen. Dennoch bleibt die Nachfrage nach Experten, die sowohl die mathematische Logik als auch die physische Speicherverwaltung beherrschen, ungebrochen hoch. Dies spiegelt sich in den überdurchschnittlich hohen Gehältern für erfahrene Datenbankadministratoren wider.
Ausblick auf zukünftige Standards und Technologien
Die Weiterentwicklung der Datenbanksprachen steht vor neuen Herausforderungen durch Quantencomputing und dezentrale Netzwerke. Die bisherige Logik basiert auf klassischen Computern, die mit Bits operieren. Quantencomputer nutzen hingegen Qubits, was völlig neue Ansätze für die Suche in großen Datenmengen erfordert. Forscher arbeiten bereits an Algorithmen, die die Vorteile der Quantenmechanik für die Datenverarbeitung nutzen können, ohne die bewährte Logik aufzugeben.
In den kommenden Jahren ist mit einer weiteren Integration von natürlichen Sprachverarbeitungsmodellen in Datenbanksysteme zu rechnen. Nutzer werden in der Lage sein, komplexe Fragen in Alltagssprache zu stellen, die das System automatisch in präzise logische Anweisungen übersetzt. Ob diese Automatisierung die Fehlerquote senkt oder neue Probleme schafft, bleibt eine der zentralen Fragen für die Branche. Die Standardisierungsgremien werden weiterhin eine entscheidende Rolle dabei spielen, die Balance zwischen Innovation und Stabilität zu halten.



