In der Softwareentwicklung hat die effiziente Speicherung von Datenstrukturen für die langfristige Archivierung und Systemstabilität an Bedeutung gewonnen. Entwickler weltweit setzen verstärkt auf Methoden für Write Python List To File, um Informationen aus dem flüchtigen Arbeitsspeicher in dauerhafte Speicherformate zu überführen. Laut dem Jahresbericht der Python Software Foundation stieg die Nutzung der Sprache im Bereich Datenanalyse und Automatisierung im vergangenen Jahr um 15 Prozent. Diese Entwicklung zwingt Ingenieure dazu, standardisierte Verfahren für den Export von Listenobjekten anzuwenden, um die Interoperabilität zwischen verschiedenen Systemkomponenten zu gewährleisten.
Die Notwendigkeit einer präzisen Datenausgabe ergibt sich aus der zunehmenden Komplexität moderner Anwendungen in der Cloud-Infrastruktur. Das technische Komitee der International Organization for Standardization betont, dass die Wahl des Dateiformats die langfristige Lesbarkeit von Forschungsdaten maßgeblich beeinflusst. Während einfache Textdateien für menschliche Leser geeignet sind, bevorzugen Systemarchitekten oft serialisierte Formate wie JSON oder Pickle für den maschinellen Austausch. Die Implementierung dieser Prozesse erfolgt meist über integrierte Funktionen, die einen direkten Zugriff auf das Dateisystem des Betriebssystems ermöglichen.
Technologische Grundlagen Für Write Python List To File
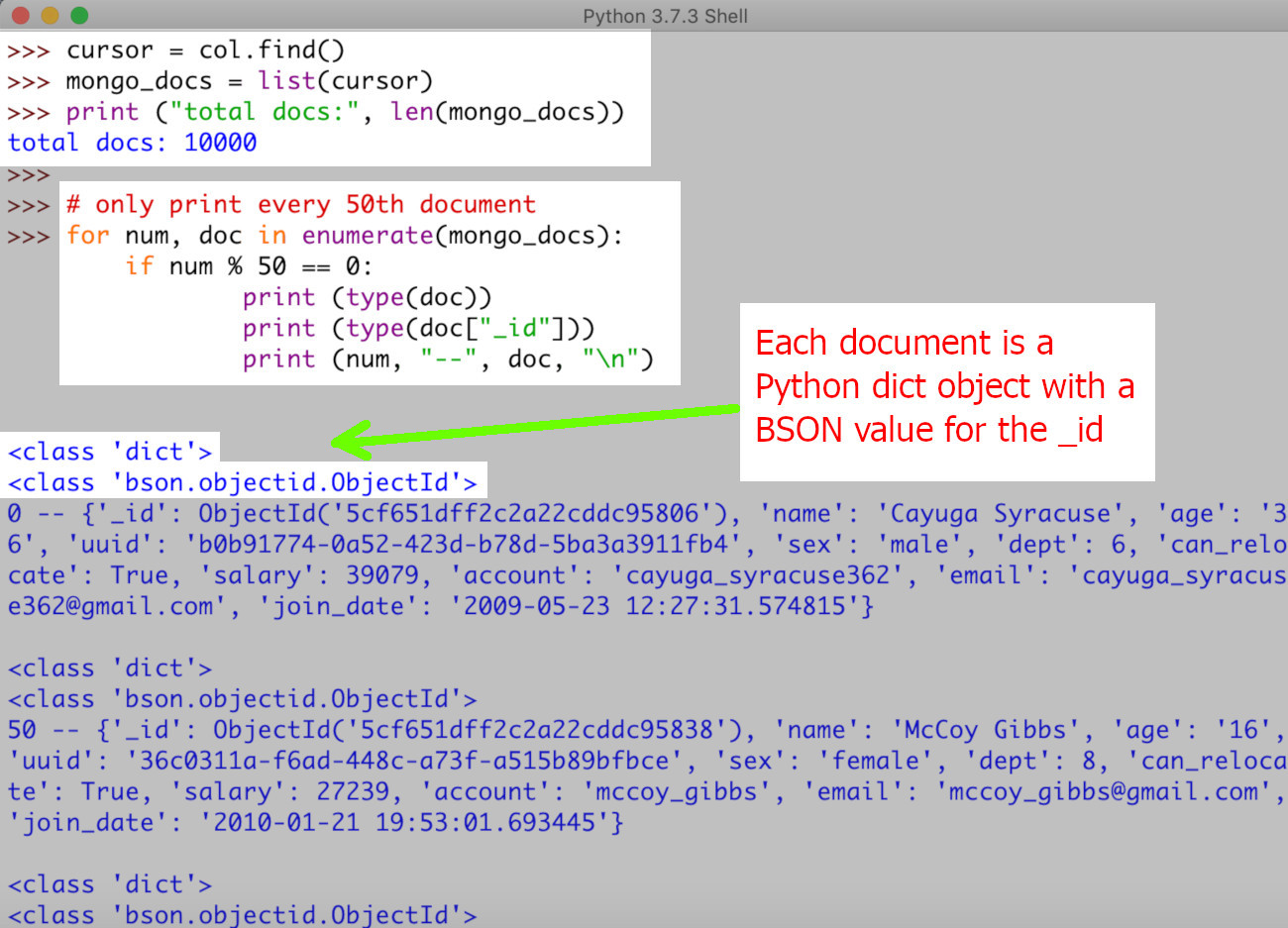
Die technische Umsetzung der Datenspeicherung basiert auf dem Prinzip der Stream-Verarbeitung, bei der Informationen sequenziell auf einen Datenträger geschrieben werden. Dokumentationen der Python-Entwicklergemeinschaft beschreiben den Prozess als eine Abfolge von Öffnen, Schreiben und Schließen eines Dateiobjekts. Ein wesentlicher Aspekt ist hierbei die Kodierung der Zeichenfolgen, wobei der Standard UTF-8 eine breite Kompatibilität über verschiedene Plattformen hinweg bietet. Ohne eine explizite Definition der Kodierung riskieren Entwickler den Verlust von Sonderzeichen und eine fehlerhafte Darstellung in Zielanwendungen.
Formatierung Und Strukturierung Der Ausgabedaten
Innerhalb der technischen Spezifikationen unterscheiden Experten zwischen der zeilenweisen Speicherung und der strukturierten Ablage. Bei der zeilenweisen Methode wird jedes Element der Liste durch ein Trennzeichen wie einen Zeilenumbruch separiert, was die spätere Verarbeitung durch Kommandozeilenwerkzeuge erleichtert. Im Gegensatz dazu erlaubt die Verwendung von strukturierten Formaten die Beibehaltung der ursprünglichen Datentypen innerhalb der Liste. Ein illustrative Beispiel zeigt, dass eine Liste von Ganzzahlen beim Schreiben in eine Textdatei standardmäßig in Zeichenfolgen umgewandelt werden muss, was bei der Rücklesung eine erneute Konvertierung erfordert.
Effizienzsteigerung In Der Datenarchivierung
Die Optimierung der Speicherprozesse spielt eine zentrale Rolle bei der Bewältigung großer Datenmengen in der industriellen Fertigung. Laut einer Analyse von Statista wächst das globale Datenvolumen bis zum Jahr 2025 auf über 180 Zettabyte an. Unternehmen wie die SAP SE integrieren automatisierte Skripte in ihre Workflows, um Protokolldaten effizient aus den Anwendungsschichten zu exportieren. Die Technik für Write Python List To File ermöglicht es dabei, Zwischenergebnisse von Berechnungen schnell zu sichern, ohne die Hauptdatenbank zu belasten.
Die Performance der Schreibvorgänge hängt maßgeblich von der verwendeten Hardware und der Effizienz des Dateisystems ab. Benchmarks auf Plattformen wie Phoronix zeigen deutliche Unterschiede in der Schreibgeschwindigkeit zwischen traditionellen Festplatten und modernen NVMe-Speichermedien. Systemadministratoren müssen daher die Puffergröße der Schreibvorgänge anpassen, um die Belastung der Hardware zu minimieren. Ein falsch konfigurierter Exportprozess kann zu einer hohen Fragmentierung des Dateisystems führen, was die Systemleistung über einen längeren Zeitraum beeinträchtigt.
Sicherheitsrisiken Und Komplikationen Bei Der Serialisierung
Trotz der weitreichenden Vorteile warnen Sicherheitsexperten vor den Risiken bestimmter Speichermethoden. Das Bundesamt für Sicherheit in der Informationstechnik weist in seinen Leitfäden darauf hin, dass die Deserialisierung von Daten aus unsicheren Quellen ein erhebliches Sicherheitsrisiko darstellt. Besonders das Pickle-Format ist in der Kritik, da es die Ausführung von beliebigem Code während des Ladevorgangs ermöglichen kann. Entwickler werden daher dazu angehalten, auf sicherere Alternativen wie JSON oder XML auszuweichen, die keine ausführbaren Logiken enthalten.
Ein weiteres Problem stellt die Datenkorruption bei unvorhergesehenen Systemabbrüchen dar. Wenn ein Schreibvorgang unterbrochen wird, bleibt oft eine unvollständige Datei zurück, die von nachfolgenden Prozessen nicht mehr korrekt interpretiert werden kann. Um dieses Szenario zu verhindern, setzen professionelle Softwareentwickler auf atomare Schreiboperationen. Dabei wird die Datei zuerst unter einem temporären Namen erstellt und erst nach erfolgreichem Abschluss des Vorgangs umbenannt, um die Integrität der Bestandsdaten zu schützen.
Regulatorische Anforderungen Und Compliance
Die Speicherung von Daten unterliegt in der Europäischen Union strengen rechtlichen Rahmenbedingungen. Die Datenschutz-Grundverordnung verlangt von Organisationen, dass personenbezogene Informationen sicher gespeichert und bei Bedarf gelöscht werden. Wenn Listen mit Nutzerdaten exportiert werden, müssen diese Prozesse dokumentiert und oft verschlüsselt durchgeführt werden. Rechtsanwalt Dr. Christian Solmecke erklärte in öffentlichen Publikationen, dass Unternehmen für die Sicherheit der gesamten Datenkette verantwortlich sind.
Die Einhaltung von Industriestandards wie ISO 27001 erfordert zudem eine genaue Kontrolle über den Zugriff auf exportierte Dateien. In vielen Firmenumgebungen werden Dateiberechtigungen so konfiguriert, dass nur autorisierte Dienstkonten Schreibrechte besitzen. Dies verhindert die Manipulation von Protokolldateien durch unbefugte Dritte oder bösartige Software innerhalb des Netzwerks. Die Überprüfung dieser Zugriffsberechtigungen ist ein fester Bestandteil regelmäßiger IT-Audits in mittelständischen und großen Unternehmen.
Zukünftige Trends In Der Persistenten Speicherung
Die Evolution der Speichertechnologien wird in den kommenden Jahren voraussichtlich durch die Integration von künstlicher Intelligenz geprägt sein. Experten der Technischen Universität München untersuchen derzeit, wie intelligente Algorithmen die Platzierung von Daten auf verschiedenen Speichermedien optimieren können. Ziel ist es, den Energieverbrauch von Rechenzentren durch effizientere Schreib- und Lesevorgänge zu senken. Die herkömmliche Methode des Dateiexports wird dabei zunehmend durch speicherinterne Datenbanken und verteilte Dateisysteme ergänzt.
In der nahen Zukunft wird die Standardisierung von Austauschformaten weiter voranschreiten, um die Zusammenarbeit in globalen Forschungsprojekten zu verbessern. Die European Open Science Cloud arbeitet an Richtlinien, die den Austausch von Datensätzen zwischen verschiedenen wissenschaftlichen Disziplinen vereinfachen sollen. Unklar bleibt bisher, inwieweit neue Quantencomputer-Architekturen die bestehenden Dateisysteme und Serialisierungsmethoden verändern werden. Beobachter erwarten, dass die grundlegenden Prinzipien der Datensicherung bestehen bleiben, während die zugrunde liegende Hardware eine massive Transformation erfährt.


